
예를 들어, 사용자에게 게시글 목록을 조회한다고 했을 때 한 화면에 10개씩 데이터를 보여주려고 한다.
그런데 이때 클라이언트가 서버에게 DB에 존재하는 모든 게시글을 받아온다면 어떻게 될까?
성능이 매우매우 떨어질 것이다. 게시글 개수가 수백만,, 더 나아가 여러 사용자가 동시에 게시글 목록을 조회한다면
DB에 많은 부하가 걸릴 것이다..
이렇게 부하와 데이터 로딩 속도를 효율적으로 조절해주기 위해 등장한 것이 페이지네이션!
🪽 페이징(Paginatinon)
데이터를 쪼개서 일부만 가져오는 기법
크게 offset 기반 페이징과, cursor 기반 페이징이 있다.
🪽 offset 페이징
- offset : 어디부터 시작해서 가져올것인지?
- limit : 몇개의 데이터를 가져올 것인지?
SELECT *
FROM product
ORDER BY id DESC
OFFSET pageNum * pageSize
LIMIT pageSizeSELECT * FROM product LIMIT {페이지 당 출력할 자료 갯수} OFFSET {오프셋}
SELECT * FROM product LIMIT 40 OFFESET 0; # 1~40 출력
SELECT * FROM product LIMIT 40 OFFESET 40; # 41~80 출력
SELECT * FROM product LIMIT 40 OFFESET 80; # 41~80 출력출처: https://bestsu.tistory.com/98 [SoooooJJANG:티스토리]
우리가 흔히 아는 게시판 페이지 번호를 클릭해서 데이터를 조회하는 게 offset방식으로 동작하는 대표적인 예시이다.
🪽 offset 페이징의 동작
SELECT * FROM product LIMIT 10 OFFESET 5000;
해당 코드를 예시로 보자. 데이터가 1번부터 시작한다고 보았을때, 위 코드는 5001번째 데이터 부터 10개의 데이터를 조회하게 된다.
근데 단순히 10개의 데이터만 조회할까? 답은 아니다.
offset 기반 페이징은 데이터를 조회 한 후 limit으로 지정한 개수만 사용하고, 나머지는 버리는 방식으로 동작한다. 위의 쿼리를 예로 들면 5000번째 데이터부터 10개를 조회하기 위해서는 5010개의 데이터를 모두 읽은 뒤, 앞의 필요하지 않은 5000개는 버리게 된다.
즉, offset 방식은 offset 이전의 데이터를 모두 조회하고 필요없는 데이터는 버리는 "스캔 후 버리기" 방식으로 동작한다.
🪽 offset 페이징의 단점
✅ 1. 데이터의 잦은 추가와 삭제가 이루어질 때 데이터 누락과 중복이 발생할 수 있다.
만약 특정 페이지에서 다음 페이지로 넘어가는 사이에 새로운 row가 추가되면 어떻게 될까?
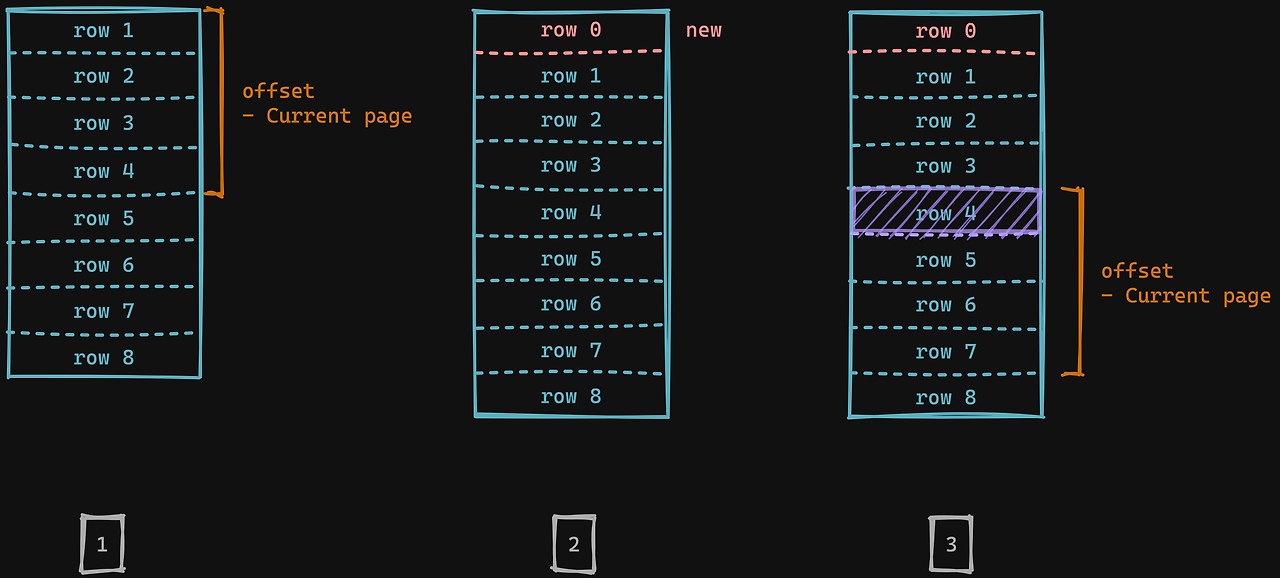
1페이지에서 조회했던, 4번행을 2페이지에서도 조회하게 되는 결과를 초래한다.
아래를 예시로 더 자세히 살펴보자.
(1) 데이터가 추가되었을 때
- 초기 데이터 상태
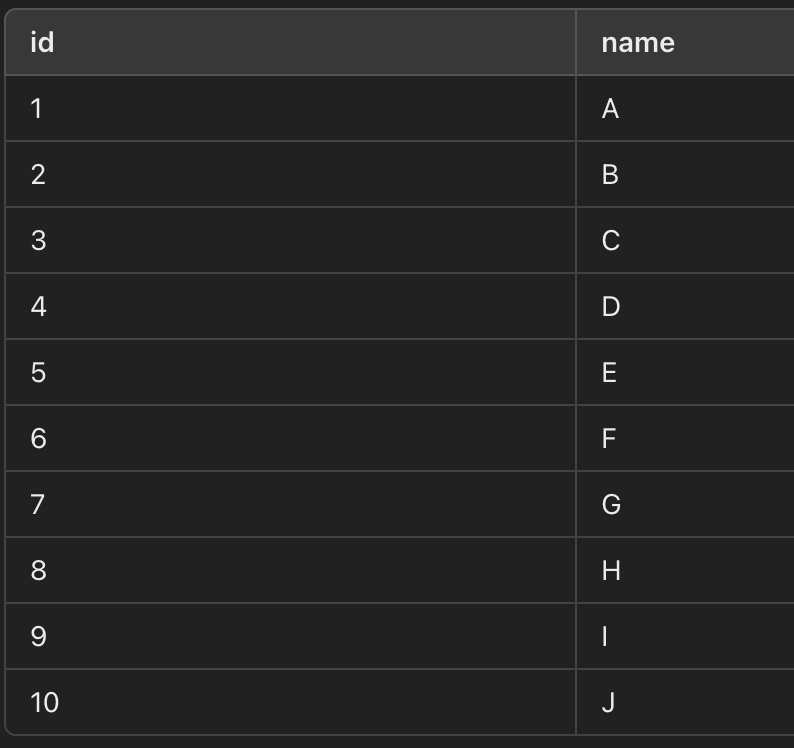
✅ 첫 번째 페이지 (LIMIT 5 OFFSET 0)
SELECT * FROM users ORDER BY id ASC LIMIT 5 OFFSET 0;
결과)
| id | name |
| 1 | A |
| 2 | B |
| 3 | C |
| 4 | D |
| 5 | E |
✅ 두 번째 페이지 (LIMIT 5 OFFSET 5)
SELECT * FROM users ORDER BY id ASC LIMIT 5 OFFSET 5;
결과)
| id | name |
| 6 | F |
| 7 | G |
| 8 | H |
| 9 | I |
| 10 | J |
🚨 문제 발생: 만약 id=4와 id=5 사이에 새로운 데이터 (id=4.5)가 추가되면? 새로운 데이터(id=4.5)가 추가되었다고 가정하자.
id가 4.5로 저장되지 않겠지만.. 이해를 돕기위해 가정해봅시다.
| id | name |
| 1 | A |
| 2 | B |
| 3 | C |
| 4 | D |
| 4.5 | NEW |
| 5 | E |
| 6 | F |
| 7 | G |
| 8 | H |
| 9 | I |
| 10 | J |
이제 다시 두 번째 페이지 (OFFSET 5 사용)를 조회하면
SELECT * FROM users ORDER BY id ASC LIMIT 5 OFFSET 5;| id | name |
| 5 | E |
| 6 | F |
| 7 | G |
| 8 | H |
| 9 | I |
🔥 id=5가 두 번째 페이지에서 다시 나와버리면서, 중복 문제가 발생하게 된다.
✅ 2. offset이 커질수록 데이터 조회 성능이 저하된다.
이 얘기는 offset의 동작과 자연스럽게 이어지는 얘기다. 조회하고자 하는 값의 이전 데이터들이 불필요함에도 불구하고, 모두 순차 스캔하므로 성능이 저하되게 된다.
offset이 커질 수록 얼마나 성능차이가 나는지는, 곧 추가로 정리해놓겠습니다... ㅎㅎ
*참고로 spring 프레임워크의 pageable은 offset방식이다
🪽 cusor 페이징
cursor가 가리키는 레코드로부터 일정 갯수만큼 가져오는 방식
클라이언트에게 전달한 마지막 데이터 다음 번 데이터 부터 조회한다.
- 실시간 데이터와 대량의 데이터(페이스북, 슬랙 , 트위터 등)을 다루는 웹사이트에서 쓰이는 페이징 방법
- 프론트에서 무한 스크롤(인스타 그램, 페이스북처럼 하단으로 계속 스크롤 되는 페이징 방식)을 지원
SELECT * FROM product WHERE id > {기준값} LIMIT 40;
여기서 기준값이란 마지막 데이터의 id값이 된다.
🪽 cusor 값이 unquie 하지 않을 때 발생할 수 있는 문제
- 중복된 데이터를 다시 가져올 가능성이 있음 (중복 문제)
- 일부 데이터를 건너뛸 가능성이 있음 (누락 문제)
예제 -> created_at을 커서로 사용했을 때 발생하는 문제
(1) 데이터 테이블
| id | title | created_at |
| 1 | Post A | 2024-02-15 10:00:00 |
| 2 | Post B | 2024-02-15 10:00:00 |
| 3 | Post C | 2024-02-15 10:00:00 |
| 4 | Post D | 2024-02-15 10:00:00 |
| 5 | Post E | 2024-02-15 10:00:01 |
✅ 첫 번째 페이지 요청
SELECT * FROM post
ORDER BY created_at ASC
LIMIT 2;
결과)
| id | title | created_at |
| 1 | Post A | 2024-02-15 10:00:00 |
| 2 | Post B | 2024-02-15 10:00:00 |
📌 이제 cursor = 2024-02-15 10:00:00을 저장하고, 다음 페이지에서 이를 기준으로 조회하면?
✅ 두 번째 페이지 요청
SELECT * FROM post
WHERE created_at > '2024-02-15 10:00:00'
ORDER BY created_at ASC
LIMIT 2;
결과)
| id | title | created_at |
| 5 | PostE | 2024-02-15 10:00:01 |
🔥 문제
- cursor가 unqiue하지 않다면, 다음과 같이 데이터 누락 문제가 발생할 수 있다!
참고한 글
offset과 no offset을 사용한 페이징 성능 차이 분석
서론 최근 진행했던 식도락 프로젝트에서 유저의 피드 목록을 페이징 처리를 하여 제공하는 api를 개발했습니다. 해당 api는 sns 특성상 페이지 단위로 제공하기보다는 무한 스크롤 형식에 최근
forkyy.tistory.com
Cursor based Pagination(커서 기반 페이지네이션)이란? - Querydsl로 무한스크롤 구현하기
Cursor based Pagination, 커서 기반 페이징, 무한스크롤
velog.io
'백엔드 > SpringBoot' 카테고리의 다른 글
| [Spring Boot] HTTP 요청/응답 로깅 (0) | 2025.04.05 |
|---|---|
| 스프링 AOP와 트랜잭션 (0) | 2025.02.12 |
| 멀티스레드 환경에서의 트랜잭션 동작 - feat. 테스트 코드 (0) | 2025.02.10 |
| ② 실전! 스프링 부트와 JPA 활용1 (1) | 2023.11.14 |
| ① 실전! 스프링 부트와 JPA 활용1 (2) | 2023.11.06 |
예를 들어, 사용자에게 게시글 목록을 조회한다고 했을 때 한 화면에 10개씩 데이터를 보여주려고 한다.
그런데 이때 클라이언트가 서버에게 DB에 존재하는 모든 게시글을 받아온다면 어떻게 될까?
성능이 매우매우 떨어질 것이다. 게시글 개수가 수백만,, 더 나아가 여러 사용자가 동시에 게시글 목록을 조회한다면
DB에 많은 부하가 걸릴 것이다..
이렇게 부하와 데이터 로딩 속도를 효율적으로 조절해주기 위해 등장한 것이 페이지네이션!
🪽 페이징(Paginatinon)
데이터를 쪼개서 일부만 가져오는 기법
크게 offset 기반 페이징과, cursor 기반 페이징이 있다.
🪽 offset 페이징
- offset : 어디부터 시작해서 가져올것인지?
- limit : 몇개의 데이터를 가져올 것인지?
SELECT *
FROM product
ORDER BY id DESC
OFFSET pageNum * pageSize
LIMIT pageSizeSELECT * FROM product LIMIT {페이지 당 출력할 자료 갯수} OFFSET {오프셋}
SELECT * FROM product LIMIT 40 OFFESET 0; # 1~40 출력
SELECT * FROM product LIMIT 40 OFFESET 40; # 41~80 출력
SELECT * FROM product LIMIT 40 OFFESET 80; # 41~80 출력출처: https://bestsu.tistory.com/98 [SoooooJJANG:티스토리]
우리가 흔히 아는 게시판 페이지 번호를 클릭해서 데이터를 조회하는 게 offset방식으로 동작하는 대표적인 예시이다.
🪽 offset 페이징의 동작
SELECT * FROM product LIMIT 10 OFFESET 5000;
해당 코드를 예시로 보자. 데이터가 1번부터 시작한다고 보았을때, 위 코드는 5001번째 데이터 부터 10개의 데이터를 조회하게 된다.
근데 단순히 10개의 데이터만 조회할까? 답은 아니다.
offset 기반 페이징은 데이터를 조회 한 후 limit으로 지정한 개수만 사용하고, 나머지는 버리는 방식으로 동작한다. 위의 쿼리를 예로 들면 5000번째 데이터부터 10개를 조회하기 위해서는 5010개의 데이터를 모두 읽은 뒤, 앞의 필요하지 않은 5000개는 버리게 된다.
즉, offset 방식은 offset 이전의 데이터를 모두 조회하고 필요없는 데이터는 버리는 "스캔 후 버리기" 방식으로 동작한다.
🪽 offset 페이징의 단점
✅ 1. 데이터의 잦은 추가와 삭제가 이루어질 때 데이터 누락과 중복이 발생할 수 있다.
만약 특정 페이지에서 다음 페이지로 넘어가는 사이에 새로운 row가 추가되면 어떻게 될까?
1페이지에서 조회했던, 4번행을 2페이지에서도 조회하게 되는 결과를 초래한다.
아래를 예시로 더 자세히 살펴보자.
(1) 데이터가 추가되었을 때
- 초기 데이터 상태
✅ 첫 번째 페이지 (LIMIT 5 OFFSET 0)
SELECT * FROM users ORDER BY id ASC LIMIT 5 OFFSET 0;
결과)
| id | name |
| 1 | A |
| 2 | B |
| 3 | C |
| 4 | D |
| 5 | E |
✅ 두 번째 페이지 (LIMIT 5 OFFSET 5)
SELECT * FROM users ORDER BY id ASC LIMIT 5 OFFSET 5;
결과)
| id | name |
| 6 | F |
| 7 | G |
| 8 | H |
| 9 | I |
| 10 | J |
🚨 문제 발생: 만약 id=4와 id=5 사이에 새로운 데이터 (id=4.5)가 추가되면? 새로운 데이터(id=4.5)가 추가되었다고 가정하자.
id가 4.5로 저장되지 않겠지만.. 이해를 돕기위해 가정해봅시다.
| id | name |
| 1 | A |
| 2 | B |
| 3 | C |
| 4 | D |
| 4.5 | NEW |
| 5 | E |
| 6 | F |
| 7 | G |
| 8 | H |
| 9 | I |
| 10 | J |
이제 다시 두 번째 페이지 (OFFSET 5 사용)를 조회하면
SELECT * FROM users ORDER BY id ASC LIMIT 5 OFFSET 5;| id | name |
| 5 | E |
| 6 | F |
| 7 | G |
| 8 | H |
| 9 | I |
🔥 id=5가 두 번째 페이지에서 다시 나와버리면서, 중복 문제가 발생하게 된다.
✅ 2. offset이 커질수록 데이터 조회 성능이 저하된다.
이 얘기는 offset의 동작과 자연스럽게 이어지는 얘기다. 조회하고자 하는 값의 이전 데이터들이 불필요함에도 불구하고, 모두 순차 스캔하므로 성능이 저하되게 된다.
offset이 커질 수록 얼마나 성능차이가 나는지는, 곧 추가로 정리해놓겠습니다... ㅎㅎ
*참고로 spring 프레임워크의 pageable은 offset방식이다
🪽 cusor 페이징
cursor가 가리키는 레코드로부터 일정 갯수만큼 가져오는 방식
클라이언트에게 전달한 마지막 데이터 다음 번 데이터 부터 조회한다.
- 실시간 데이터와 대량의 데이터(페이스북, 슬랙 , 트위터 등)을 다루는 웹사이트에서 쓰이는 페이징 방법
- 프론트에서 무한 스크롤(인스타 그램, 페이스북처럼 하단으로 계속 스크롤 되는 페이징 방식)을 지원
SELECT * FROM product WHERE id > {기준값} LIMIT 40;
여기서 기준값이란 마지막 데이터의 id값이 된다.
🪽 cusor 값이 unquie 하지 않을 때 발생할 수 있는 문제
- 중복된 데이터를 다시 가져올 가능성이 있음 (중복 문제)
- 일부 데이터를 건너뛸 가능성이 있음 (누락 문제)
예제 -> created_at을 커서로 사용했을 때 발생하는 문제
(1) 데이터 테이블
| id | title | created_at |
| 1 | Post A | 2024-02-15 10:00:00 |
| 2 | Post B | 2024-02-15 10:00:00 |
| 3 | Post C | 2024-02-15 10:00:00 |
| 4 | Post D | 2024-02-15 10:00:00 |
| 5 | Post E | 2024-02-15 10:00:01 |
✅ 첫 번째 페이지 요청
SELECT * FROM post
ORDER BY created_at ASC
LIMIT 2;
결과)
| id | title | created_at |
| 1 | Post A | 2024-02-15 10:00:00 |
| 2 | Post B | 2024-02-15 10:00:00 |
📌 이제 cursor = 2024-02-15 10:00:00을 저장하고, 다음 페이지에서 이를 기준으로 조회하면?
✅ 두 번째 페이지 요청
SELECT * FROM post
WHERE created_at > '2024-02-15 10:00:00'
ORDER BY created_at ASC
LIMIT 2;
결과)
| id | title | created_at |
| 5 | PostE | 2024-02-15 10:00:01 |
🔥 문제
- cursor가 unqiue하지 않다면, 다음과 같이 데이터 누락 문제가 발생할 수 있다!
참고한 글
offset과 no offset을 사용한 페이징 성능 차이 분석
서론 최근 진행했던 식도락 프로젝트에서 유저의 피드 목록을 페이징 처리를 하여 제공하는 api를 개발했습니다. 해당 api는 sns 특성상 페이지 단위로 제공하기보다는 무한 스크롤 형식에 최근
forkyy.tistory.com
Cursor based Pagination(커서 기반 페이지네이션)이란? - Querydsl로 무한스크롤 구현하기
Cursor based Pagination, 커서 기반 페이징, 무한스크롤
velog.io
'백엔드 > SpringBoot' 카테고리의 다른 글
| [Spring Boot] HTTP 요청/응답 로깅 (0) | 2025.04.05 |
|---|---|
| 스프링 AOP와 트랜잭션 (0) | 2025.02.12 |
| 멀티스레드 환경에서의 트랜잭션 동작 - feat. 테스트 코드 (0) | 2025.02.10 |
| ② 실전! 스프링 부트와 JPA 활용1 (1) | 2023.11.14 |
| ① 실전! 스프링 부트와 JPA 활용1 (2) | 2023.11.06 |